 AiDraw
AiDraw杂项
提示词原理
图像生成器

information creator 完全在图像信息空间(或潜伏空间)中工作。这一特性使它比以前在像素空间工作的扩散模型更快。在技术上,这个组件是由一个 UNet 神经网络和一个调度算法组成的。
Text Encoder
提示词的解析由 Text Encoder/CLIP 处理 (token embedding),这里是提示词转译给 AI 的关键一步。
ClipText 用于文本编码。
输入文本,输出 77 个标记嵌入向量,每个都有 768 个维度。
information creator
UNet + Scheduler 在信息(潜在)空间中逐步处理/分散信息。
它输入文本嵌入和一个由噪声组成的起始多维数组(结构化的数字列表,也叫张量),输出一个经过处理的信息阵列。
Image Decoder
Text Decoder 根据从 information creator 那里获得的信息绘制一幅图画。 它只在过程结束时运行一次以生成最终图像。
Autoencoder Decoder 使用处理过的信息阵列绘制最终图像的解码器。输入处理过的信息阵列 (dimensions: (4,64,64)),输出结果图像 (dimensions: (3, 512, 512),即 (red/green/blue, width, height)。
CLIP 的工作
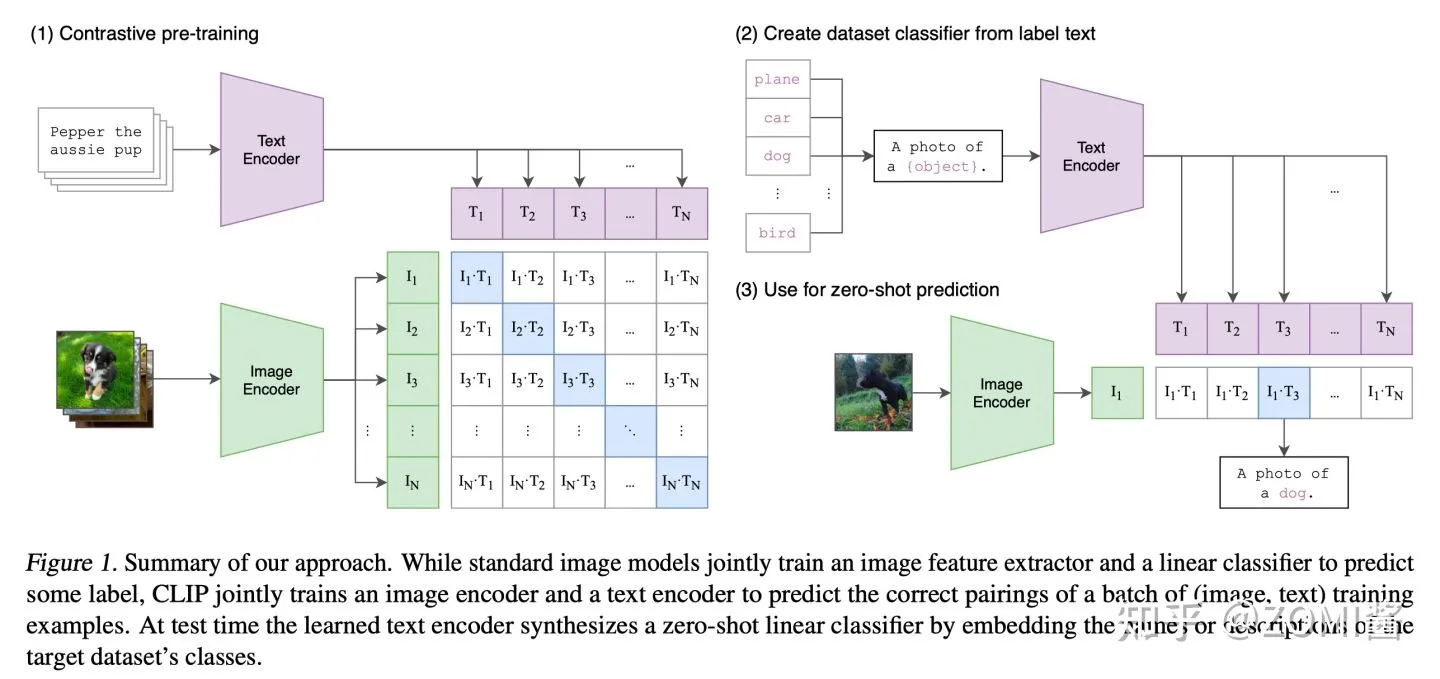
CLIP 训练图 from https://bbs.huaweicloud.com/blogs/371319
Stable Diffusion 中使用的自动编码器的缩减系数为 8。这意味着一张 (4, 512, 512) 的图像在潜在空间中是 (4, 64, 64)。
在使用稳定扩散推理一张 512 x 512 的图片的过程中,模型用一个种子和一个文本提示作为输入。潜在种子生成大小 64 × 64 的随机潜在图像,而 prompt 进入 Text Encoder 通过 CLIP 的文本编码器转化为大小为 77 × 768 的文本嵌入。
U-Net 在以文本嵌入为条件的同时迭代地对随机高斯噪声表示进行去噪。U-Net 通过 采样算法 计算去噪的潜在图像表示,输出噪声残差。这个步骤重复许多次后,潜在表示由 Image Decoder 的 auto encoder 的解码器解码输出。
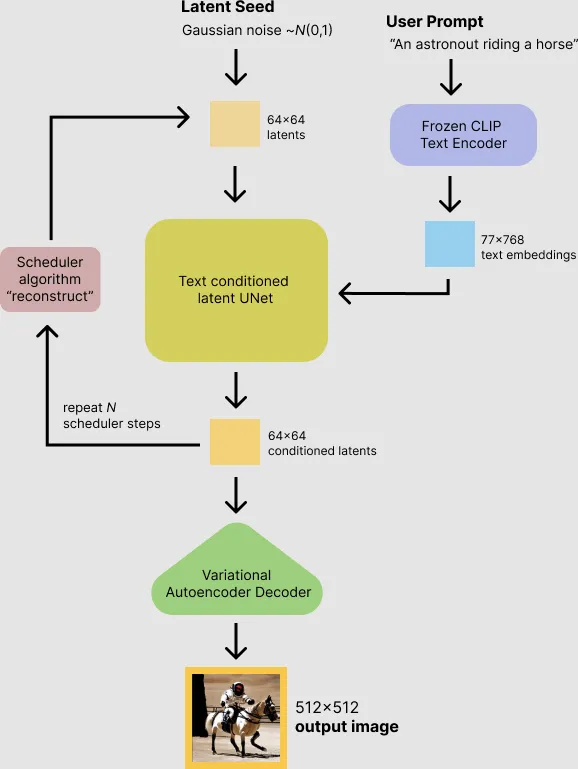
扩展阅读:
WebUI 的实现
WebUI 的 prompt_parser 通过本地 WebUI 实现了渐变等功能。
WebUI prompt 语法会转换为相应时间的 prompt,然后通过 embedding 交给 Ai 处理。
关于权重的实现:权重增加通常会占一个提示词位。
关于渐变的实现:到了指定 Step,WebUI 程序会替换对应提示词,达到渐变效果。
其他以此类推。
整个看下来,原理流程如图 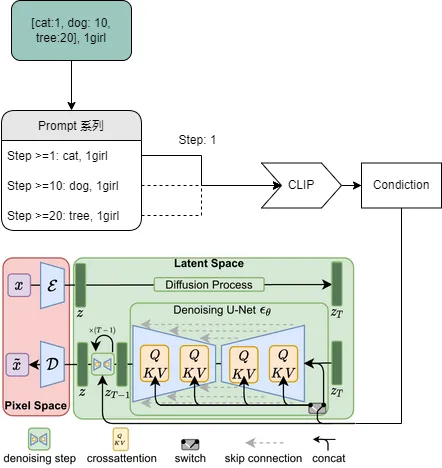
By RcINS
你可以在 illustrated-stable-diffusion 看到全面的介绍。本节部分内容也是由此翻译。
良好参数(风格趋向插画)
an extremely delicate and beautiful
草图风格
| 词 | 描述 |
|---|---|
| sketch | 可以让图片看起来像随手画的草稿 |
| lineart | 可以让线条变得很粗 |
| posing sketch, monochrome | 黑白草图 |
| rough sketch | 上了颜色的草图 |
| monochrome+lineart | 情况下一般只会让眼睛上色,强调发色后头发也可以上色 |
| monochrome, gray scale, pencil sketch lines | 做出的铅笔速写的感觉 |
利用 sketch,pastel color,lineart 的 tag 模拟一张图的绘画过程
艺术风格
| 词 | 描述 |
|---|---|
| chibi | 可以画出低头身比的效果(二头身, 三头身) |
| watercolor pencil | 可以生成彩铅画 |
| faux traditional media | 可以做出签绘的风格 |
| anime screeshot, | 可以让画面变成动画风格 |
| retro artstyle | 赛璐璐风 |
| photorealistic, painting, realistic, sketch, oil painting | 厚涂 |
| pastel color 和 sketch | 搭配会有速涂的质感 |
杂志/设定集 风格
| 词 | 描述 |
|---|---|
| official art | 变得更加官方一点 |
| three views from front, back and side 和 costume setup materials | 可以用来生成设定图 |
| multiple views | 会出现类似设定图 |
| character sheet | 会出现设定图 |
| magazine cover | 会把背景换成杂志封面, 配合 office art 更像真实杂志(虽然字没法看) |
| magazine scan | 类似杂志内页的风格 |
| posing | 会强调有一个动作, 不至于出现混乱的动作(露出有六个手指头的手) |
| caustics | 画面向主题聚焦, 类似海报 |
常用参数: SFW
| 人物数量 | 描述 |
|---|---|
| 数量 | one boy / one girl / two boy / two girl (one_boy_one_girl 是错误的) |
| 人物画风 | 描述 |
|---|---|
| 质量提升参数 | masterpiece, best quality |
| 原神 | Genshin Impact |
| 萝莉 | female child , loli (画风差) |
| 人物样貌 | 描述 |
|---|---|
| 头发 | hair |
| 长发 | longhair |
| 短发 | shorthair |
| 眼睛 | eyes |
| 渐变颜色长发 | gradient pink longhair |
| 渐变颜色眼睛 | gradient pink eyes |
| 粗眉毛 | thick eyebrows |
| 猫尾巴 | cat tail |
| 猫耳朵 | cat ears |
| 动物耳朵 | animal ears |
| 毛茸茸的动物耳朵 | animal ear fluff |
| 刘海 | bangs |
| 两眼之间的头发 | hair between eyes |
| 眉毛后面的头发 | eyebrows behind hair |
| 锁骨 | collarbone |
| 斗篷(要在很前面才有效) | cape |
| 乳房尺寸 | small breasts |
| 出汗 | sweating |
| 颜色丝袜(和长丝袜冲突) | white stockings , black stockings |
| 长丝袜 | thighhighs |
| 女仆 | maid |
| 发带 | ribbon |
| 爱心眼 | heart-shaped pupils |
| 御姐/JK/辣妹? | gyaru |
| 肌肉发达 | muscular |
| 天使翅膀(要是形容人的第一个才正常) | angel wings |
| 颜色内裤(赠内衣) | pink underpants |
| 肚脐 | navel |
| 颈部颜色项圈 | white collar |
| 黑色皮肤 | dark skin |
| 撕裂的衣服 | torn clothes |
| 撕裂的裤子 | torn legwear |
| 开襟夹克(配合叉开腿特色) | open jacket |
| 异色瞳 | heterochromia_blue_red |
| 吊袜带(会和内衣冲突) | garter straps |
| 靴子 | boots |
| 眼罩 | blindfold |
| 流泪 | tears |
| 项链 | necklace |
| 眼镜 | glasses |
| 比基尼 | bikini |
| 湿衣服 | wet clothes |
| 透明衣物 | transparent raincoat , transparent jacket , transparent tshirt |
| 唾液(自动伸舌头) | saliva |
| 流口水(和唾液冲突) | drooling |
| 水手服 | sailor dress |
| 环境样式 | 描述 |
|---|---|
| 在床上 | on bed |
| 光线反射 | reflection light |
| 赛博朋克 | cyberpunk, city, kowloon, rain |
| 在地毯上 | on carpet |
| 在瑜伽垫上(它分不清什么是瑜伽垫,只知道色块比较大,所以要配合 one girl 用) | on_yoga_mats |
| 人物视角 | 描述 |
|---|---|
| 正面视角 | from viewer |
| 从上到下视角 | from below |
| 全身 | full body |
| 人物状态 | 描述 |
|---|---|
| 叉开腿 | spread leg |
| 露出腋下 | armpits |
| 举起手 | hands up, arms up |
| 爪子手 | paw pose |
| 站立 | standing |
| 行走 | walking |
| 吐舌头 | tongue out |
| 抬起腿 | legs up |
| 手放背后 | arms behind back, hidden hands |
| 衬衫 | shirt |
| 长袖 | long sleeves |
| 连帽衫 | hoodie |
| 褶边 | frills |
| 喇叭裤 | bloomers |
| 白色连衣裙 | white dress |
| 捆绑 | bondage , bondage body , bondage foot , bondage hand |
| 蹲下 | crouch , squatting |
| 真画风 | photorealistic |
| 跪下 | kneel down |
| 湿身 | wet body |